Theory
Note
Relevant publication: Kim et al. 2020 Neural Engineering. Much of the inspiration for the derivations came from Dr. George Pappas’ course ESE 500 on Linear Systems Theory at UPenn.
When we talk about the “control” of a system, we broadly refer to some input or change to the system that alters its behavior in a desired way. To more precisely discuss control, we first have to discuss the object that is being controlled: the system. In the network control framework, what is being controlled is a dynamical system.
What is a Dynamical System?
As per the Wikipedia article on dynamical systems: “a dynamical system is a system in which a function describes the time dependence of a point in geometrical space.” We’re going to reword this sentence a bit to say: “a dynamical system is a system whose states evolve forward in time in geometric space according to a function.” Let’s unpack this sentence a bit.
“A dynamical system is a system”
The word “dynamic” (change) is used in contrast to “static” (no change). If a system is dynamic, it changes over time. That’s all well and good, but what exactly is changing about the system? The answer is: the states.
“whose states”
A state is just a complete description of a system. Take for example a train. If I know the position \(x\) of the train from some station, then I know exactly where the train is. It can only move forwards or backwards along the track, and every position along that track has an associated position \(x\), or state. As another example, in a computer, if I know the voltage of every single transistor, then I have a complete description of the computer, and I can unambiguously describe all possible states of the computer using these transistor voltages (states).
“evolve forward in time”
When we say dynamic (states are changing), we mean to say that the states are changing forward in time. Hence, time is a very important concept in dynamical systems. The field of dynamical systems broadly concerns itself with the question “how do the system states evolve forward in time?”
“in geometric space”
When we say “geometric,” we usually mean the colloquial usage of the word. That is, Euclidean space. We live in 3-dimensional Euclidean space, where every point is described by 3 coordinates: \((x,y,z)\). In a dynamical system, there is no need to restrict ourselves to 3 dimensions. In the train example, we can represent the position of the train along the track, \(x\), on a number line. Even if the track itself is not straight, we can “straighten out” the track to form a 1-dimensional line. As another exmple, the FitzHugh-Nagumo model is a 2-dimensional simplification of a Hodgkin-Huxley neuron, with two states, \(v\) and \(w\). We can plot these states separately over time (left,center), or we can plot them together in a 2-dimensional geometric space, where each axis represents either \(v\) or \(w\) (right).
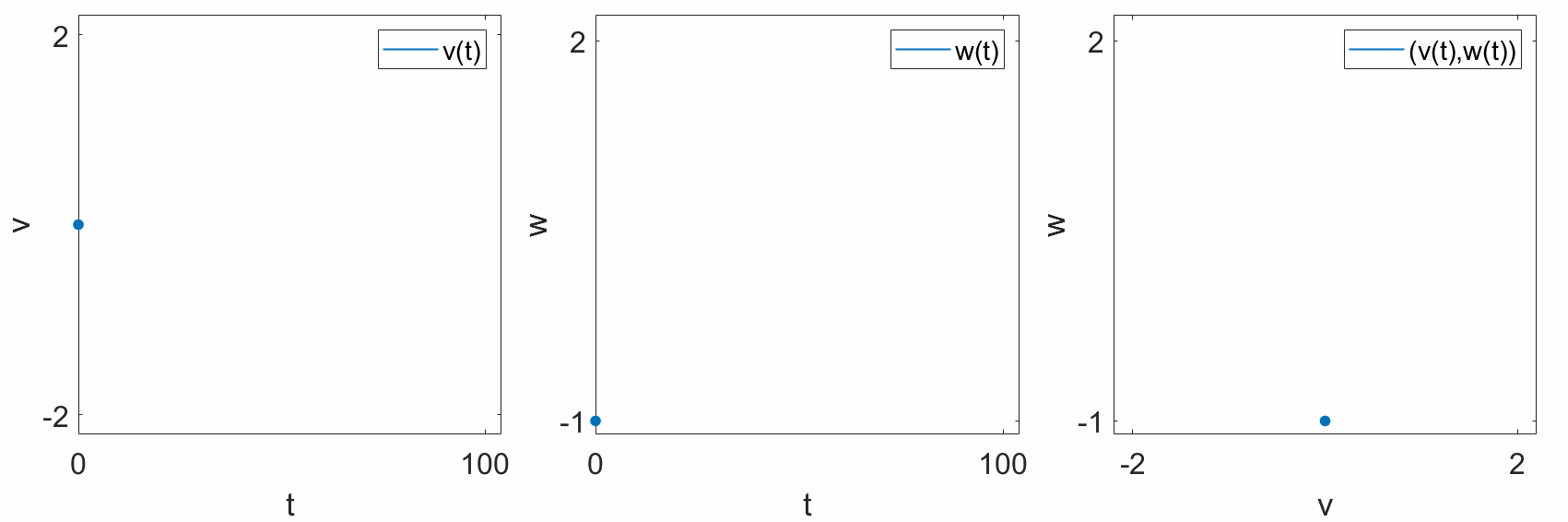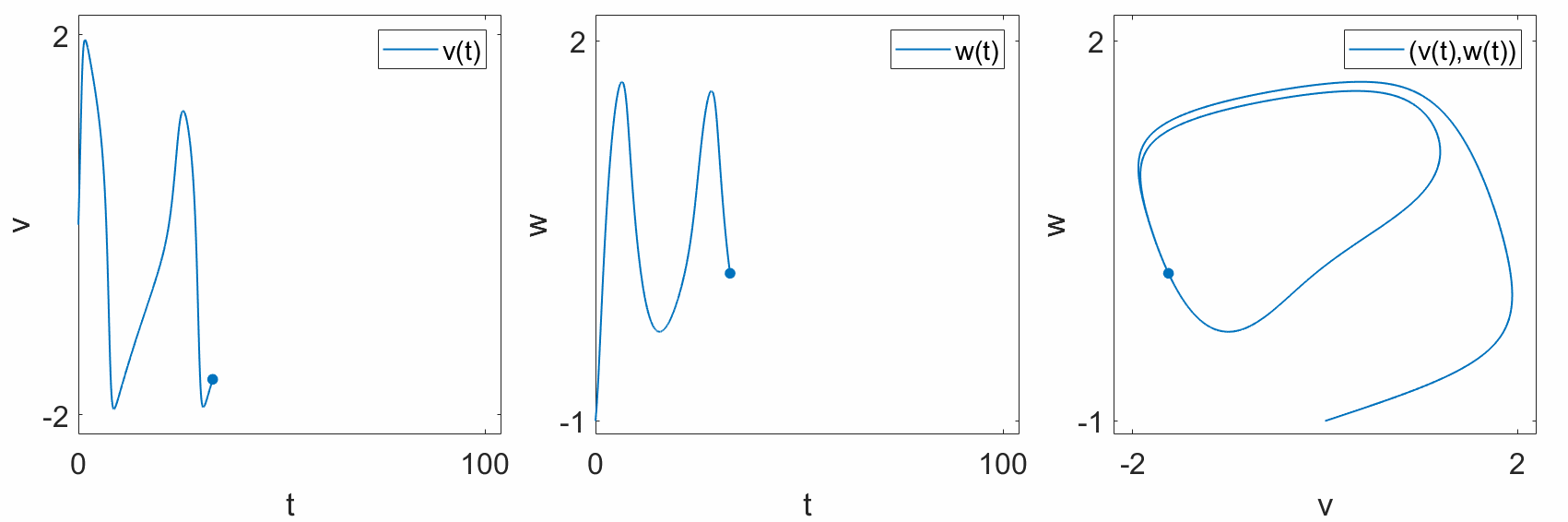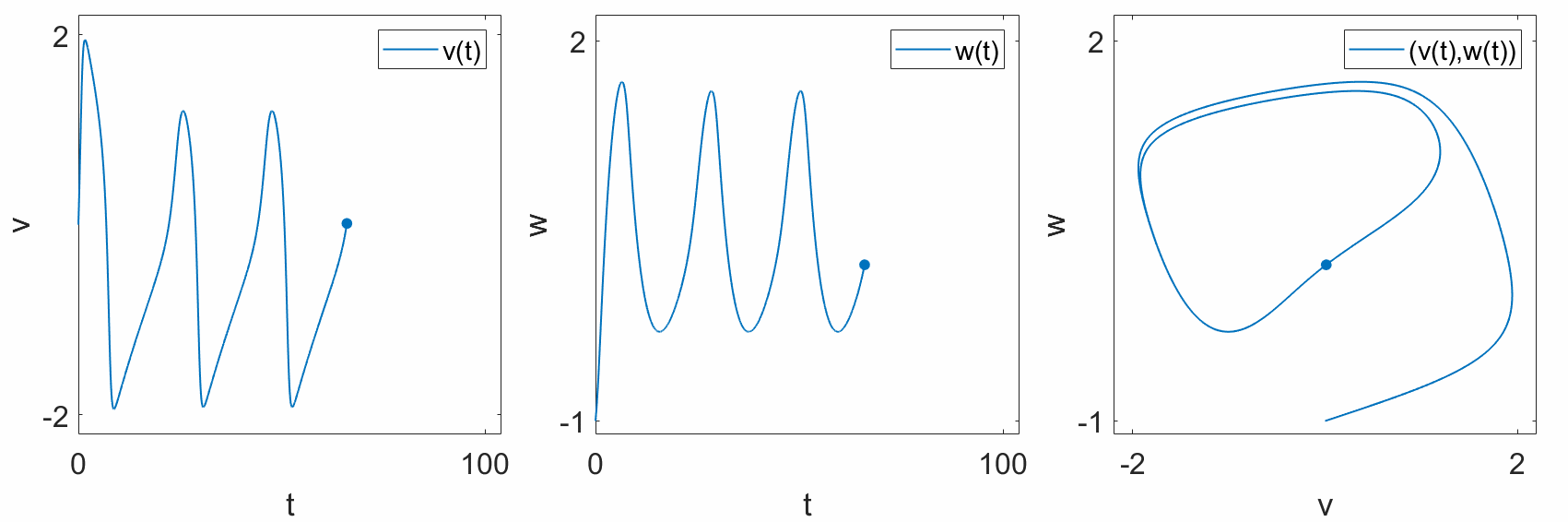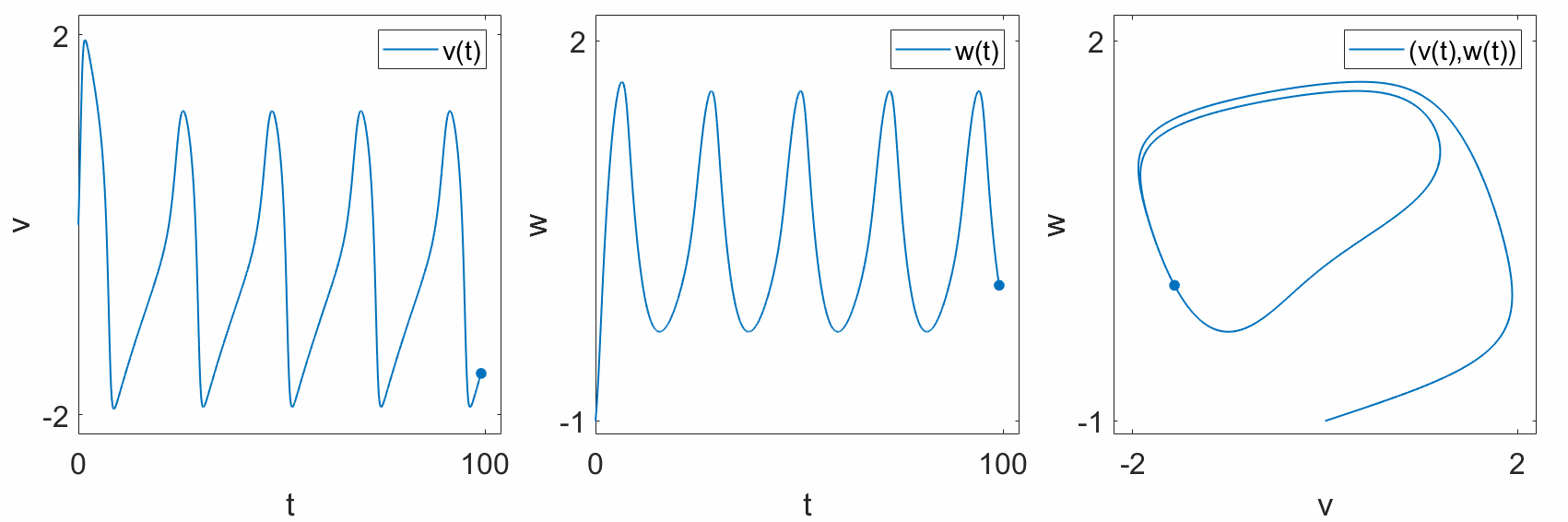
“according to a function.”
Now, just because a system has states and evolves forward in time does not make it a dynamical system. For a system to be dynamical, it must evolve forward in time according to a function. This requirement is precisely where differential equations enters the fray. Specifically, the function that the dynamical system uses to evolve forward in time is a differential equation. For example, the FitzHugh-Nagumo model evolves according to the functions
What is a Differential Equation?
As per the Wikipedia definition: “a differential equation is an equation that relates one or more functions and their derivatives.” Let’s break down this sentence.
“A differential equation is an equation”
An equation is a relation that equates the items left of the equal sign to the items right of the equal sign. For example, for a right triangle with side lengths \(a,b\) and hypotenuse length \(c\), the Pythagorean equation is:
This equation has thre evariables that are related by one equation. Hence, if I fix \(a\) and \(b,\) then I know what \(c\) has to be for the triangle to be a right triangle.
“that relates one or more functions and their derivatives.”
A derivative is an operation that tells us how a variable changes. For example, if \(c\) is a variable measuring the side length of the triangle, then \(\mathrm{d}c\) is a variable measuring the change in that side length. Typically, these change variables come as ratios to measure how quickly one variable changes with respect to another variable. For example, \(\frac{\mathrm{d}c}{\mathrm{d}a}\) is a ratio between a change in \(c\) with respect to a change in \(a\).
Dynamical Systems & Differential Equations
Recall the two statements that we have made thus far:
Dynamical system: a system whose states evolve forward in time in geometric space according to a function
Differential equation: an equation that relates one or more functions and their derivatives.
Hence the relationship between these two is that the function is a differential equation of derivatives. In particular, the derivative of the system states with respect to time.
In the differential equations of a dynamical system, the left-hand side contains a derivative of the state with respect to time, \(\frac{\mathrm{d}x}{\mathrm{d}t}.\) The right-hand side contains a function of the states, \(f(x).\) Hence, generally speaking, a dynamical equation looks like
As a specific example, let’s look at the dynamical equation
and let’s see what happens at some specific states.
If \(x=1,\) then \(\frac{\mathrm{d}x}{\mathrm{d}t} = -1.\) In other words, if the system state is at 1, then the change in state with respect to time is negative, such that the state moves towards 0.
If \(x=-1,\) then \(\frac{\mathrm{d}x}{\mathrm{d}t} = 1.\) In other words, if the system state is at -1, then the change in state with respect to time is positive, such that the state moves towards 0.
If \(x=0,\) then \(\frac{\mathrm{d}x}{\mathrm{d}t} = 0.\) The system does not change, and the state remains at 0.
If we plot the trajectories \(x(t)\) over time (left), we see that, as predicted, the trajectories all move towards \(0\) (left), and that the change in the state, \(\frac{\mathrm{d}x}{\mathrm{d}t},\) also points towards \(0\) (right).
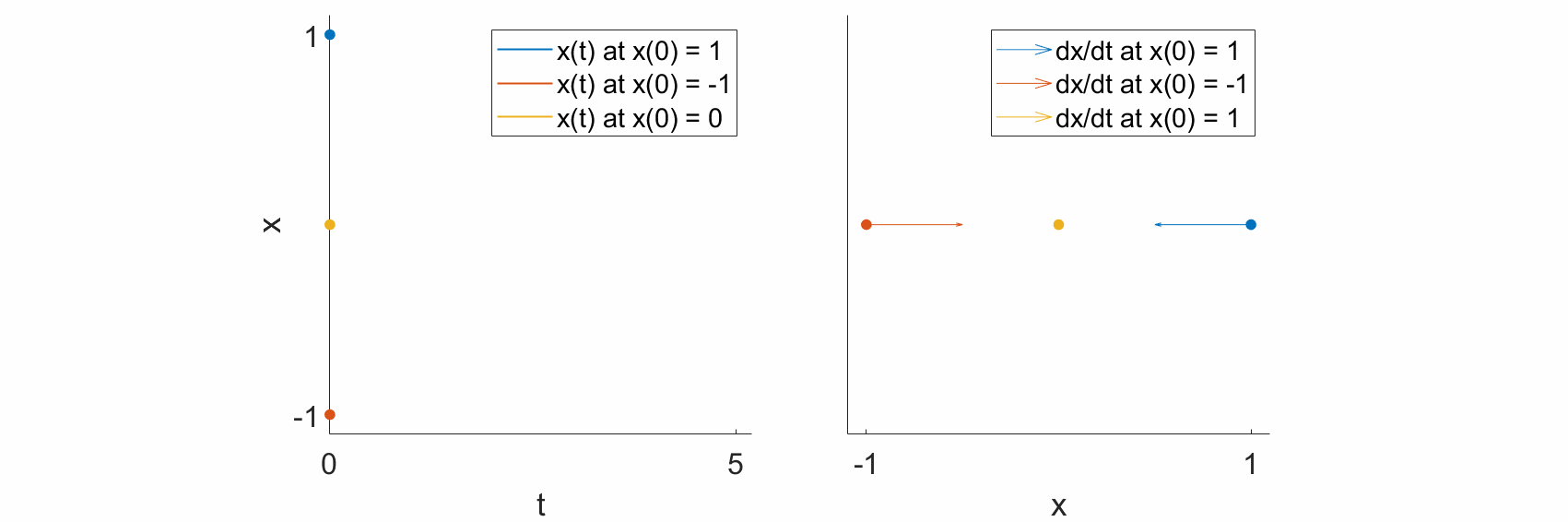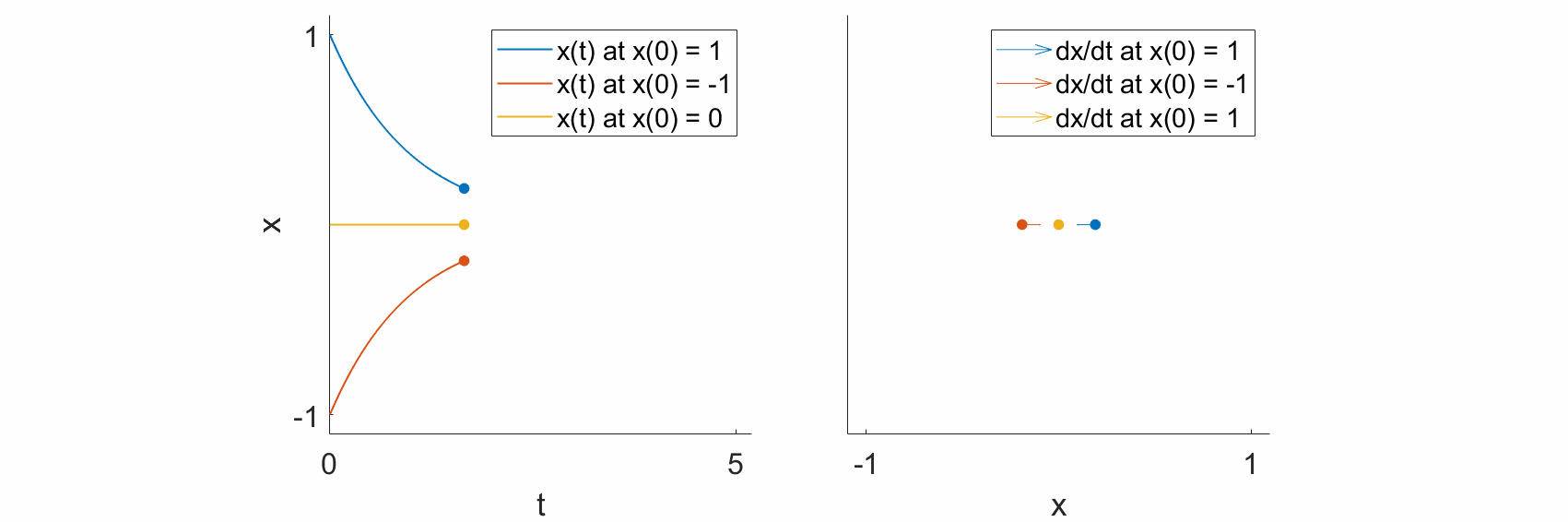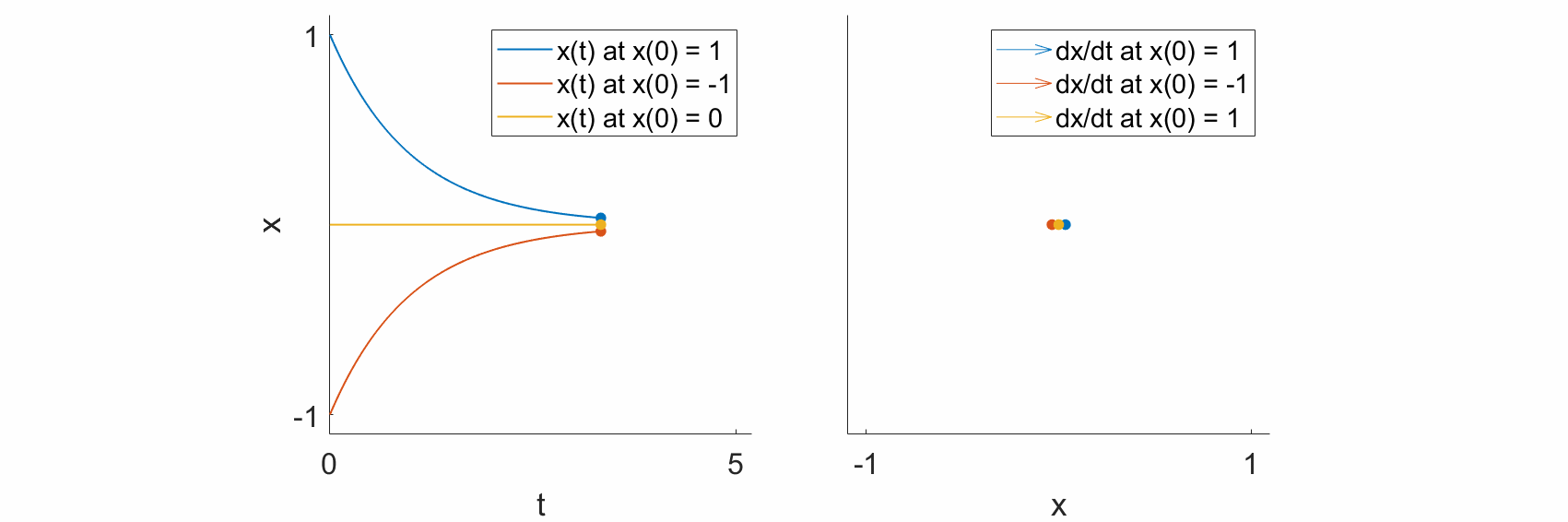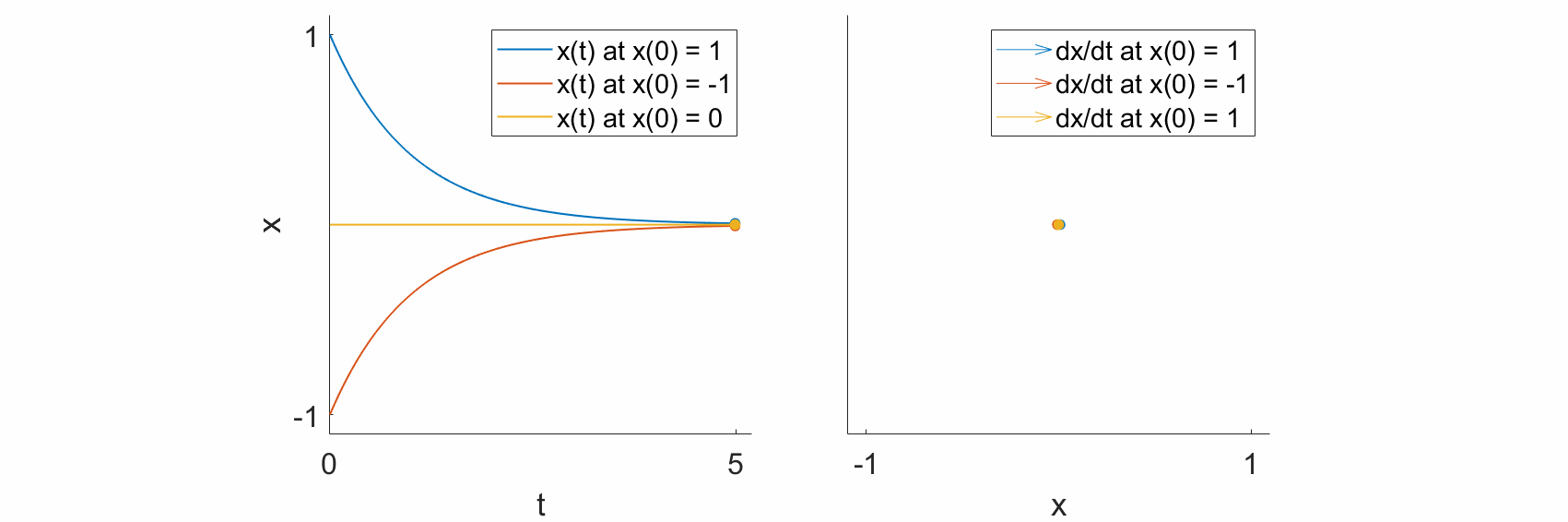
Hence, the dynamical equation for a system describes the evolution of the state at every point in state space. To visualize this description in 2-dimensions, let us revisit the equations for the FitzHugh-Nagumo model,
and at every point \((v,w)\), we will draw an arrow pointing towards \((\mathrm{d}v/\mathrm{d}t, \mathrm{d}w/\mathrm{d}t).\)
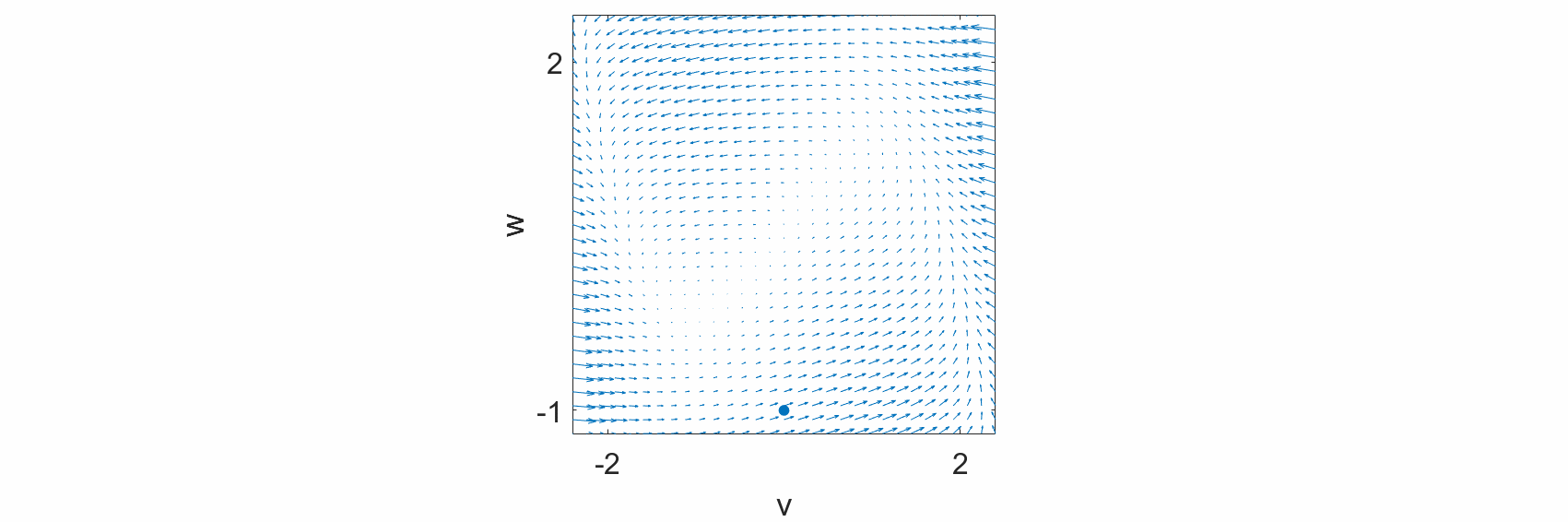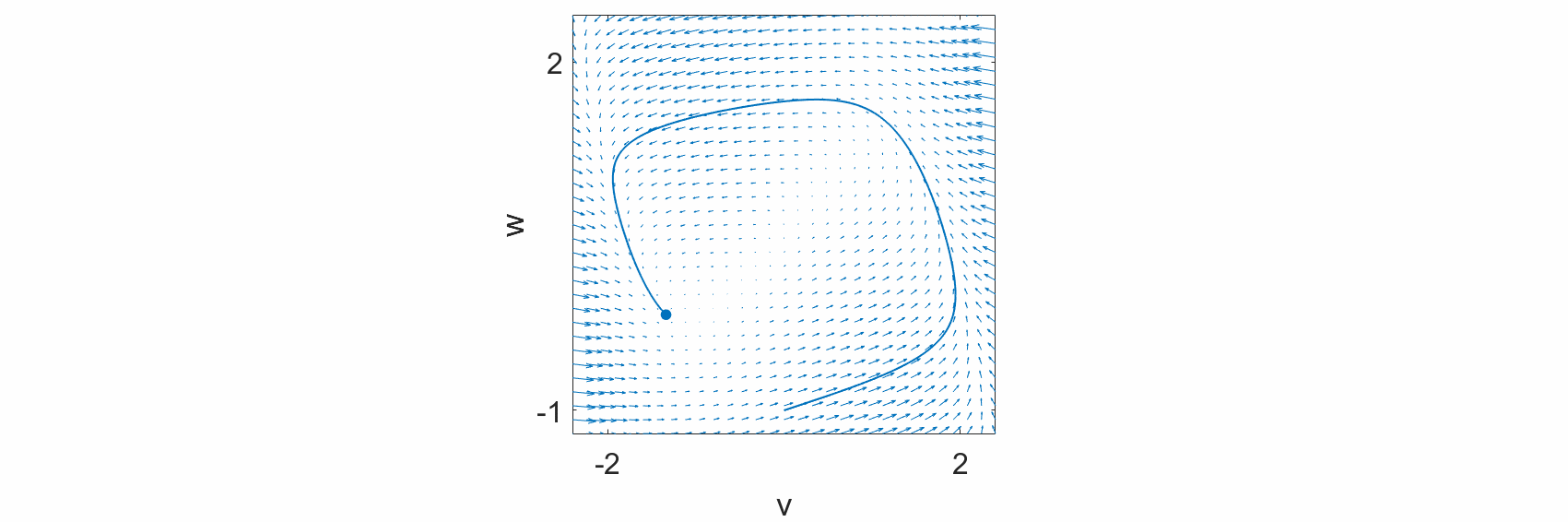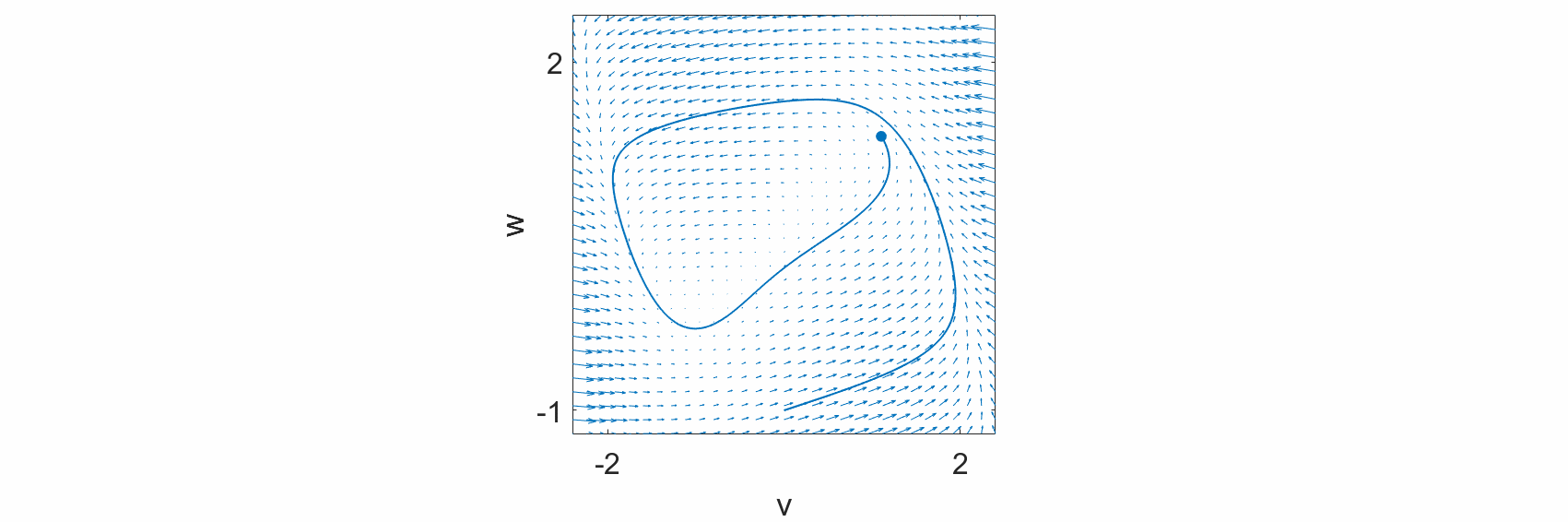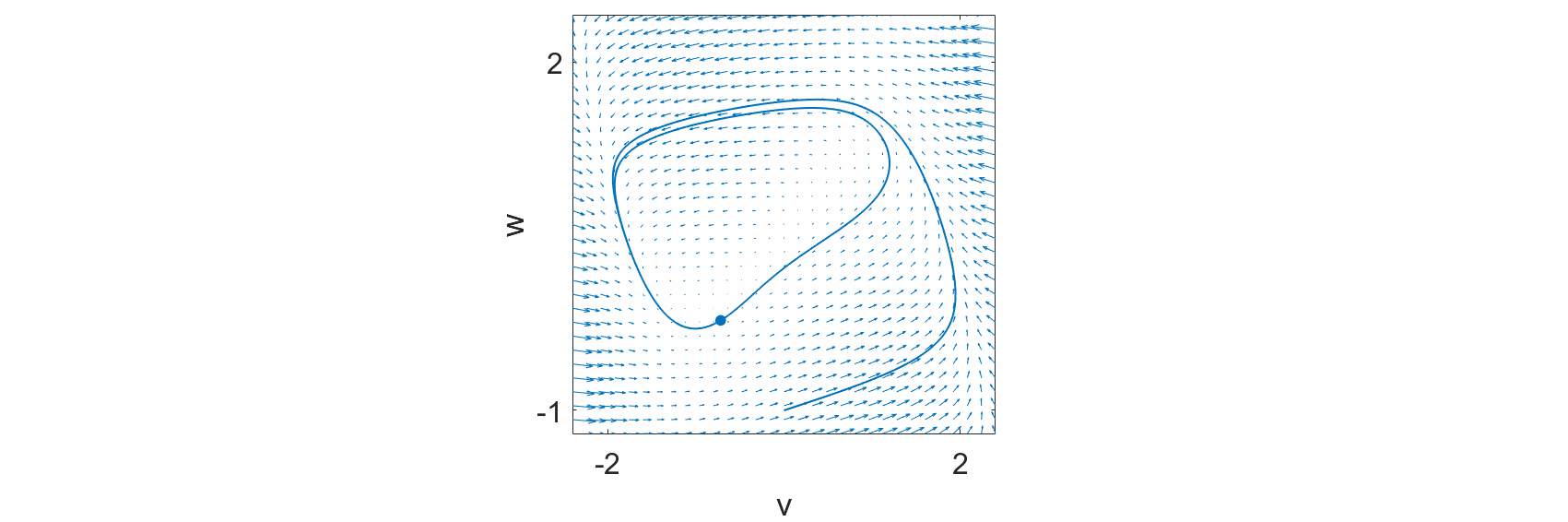
We observe that at every point in the state space, we can draw an arrow defined by the dynamical equations. Additionally, we observe that the evolution of the system states, \(v(t)\) and \(w(t),\) follow these arrows. Hence, the differential equations define the flow of the system states over time.
For convenience, we will name all of our state varibles \(x_1,x_2,\dotsm,x_N,\) and collect them into an \(N\)-dimensional vector \(\mathbf{x}.\) For an additional convenience, instead of always writing the fraction \(\frac{\mathrm{d}x}{\mathrm{d}t},\) we will use \(\dot{x}\) to represent the time derivative of \(x.\)
Linear State-Space Systems
Now that we have a better idea of what a dynamical system is, we would like to move on to control. However, there is a fundamental limitation when attempting to control a system, which is that we do not know how the system will naturally evolve. At any given state, \(\mathbf{x}(t),\) we can use the dynamical equations to know where the state will immediately go, \(\frac{\mathrm{d}\mathbf{x}(t)}{\mathrm{d}t}.\) However, we generally cannot know where the state will end up after a finite amount of time, at \(\mathbf{x}(t+T).\) This problem extends to any perturbation we perform on the system, where we cannot know how the perturbation will affect the state after a finite amount of time.
However, there is a class of dynamical systems where we can know both where the states will end up, and how a perturbation will change the states after a finite amount of time. These systems are called linear time-invariant systems, or LTI systems.
scalar LTI system
We have already looked at an example of an LTI system, namely,
We can make this system a bit more general, and look at
where \(a\) is a constant real number. Using some basic calculus, we can actually solve for the trajectory \(x(t).\) First, we divide both sides by \(x\) and multiply both sides by \(a\) to match terms,
Then, we integrate both sides,
Finally, we exponentiate both sides to pull out \(x(t)\):
where the constant \(C\) is the initial condition, \(C = x(0).\) This is because when we plug in \(t=0,\) the exponential becomes \(e^{a0} = 1.\) Hence, we can write our final trajectory as
which tells us exactly what the state of our system will be at every point in time. This knowledge of the state at every point in time is generally very difficult to obtain for nonlinear systems. To verify that this trajectory really is a solution to our dynamical equation, we can substitute it back into the differential equation, and check if the left-hand side equals the right-hand side. To evaluate the left-hand side, we must take the time derivative of \(e^{at},\) which we can do by writing the exponential as a Taylor series, such that \(e^{at} = \sum_{k=0}^\infty \frac{(at)^k}{k!}.\) Then taking the derivative of each term with respect to time, we get
Hence, the derivative of \(e^{at}\) is equal to \(ae^{at},\) such that the left-hand side of the dynamical equation equals the right-hand side.
vector LTI system
Of course, systems like the brain typically have many states, and writing down the equations for all of those states would be quite tedious. Fortunately, we can obtain all of the results in scalar LTI systems for vector LTI systems using matrix notation. In matrix form, the state-space LTI dynamics are written as
or, more compactly, as
Here, \(a_{ij}\) is the element in the \(i\)-th row and \(j\)-th column of matrix \(A,\) and represents the coupling from state \(j\) to state \(i.\)
Now, it might be too much to hope that the solution to the vector LTI system is simply a matrix version of the scalar form, perhaps something like \(\mathbf{x}(t) = e^{At}\mathbf{x}(0).\) However, this form is precisely the solution to the vector dynamical equation! Exactly as in the scalar version, we can write the matrix exponential, \(e^{At},\) as a Taylor series such that \(e^{At} = \sum_{k=0}^\infty \frac{(At)^k}{k!},\) and again take the time derivative of each term to get
Hence, the trajectory of a vector LTI system is given simply by
In general, \(e^{At}\) is called the impulse response of the system, because for any impulse \(\mathbf{x}(0),\) the impulse response tells us precisely how the system will evolve.
The Potential of Linear Response
Until now, we have written down several examples of systems that we have called linear. Drawing on our prior coursework in linear algebra, we recall that the adjective linear is used to describe a particular property of some operator \(f(\cdot)\) acting on some objects \(x_1,x_2.\) That is, if
then \(f(\cdot)\) is linear if
Colloquially, if an operator is linear, then it adds distributively. Scaling the input by a constant scales the output by the same constant, and the sum of two inputs yields the sum of the outputs.
So then, what do we mean when we say that our dynamical system is linear? In this case, we mean that the impulse response is linear. That is, for two initial conditions, \(\mathbf{x}_1(0), \mathbf{x}_2(0),\) if
then
which is true by the distributive property.
a 2-state example
While this property might not seem so impressive at first glance, the implications are actually quite powerful. Specifically, this linearity allows us to write all possible trajectories of our system as a simple weighted sum of initial conditions. Hence, rather than having to simulate all initial states to see if we reach a particular final state, we can reconstruct the initial state that yields a desired final state. To demonstrate, consider the following simple 2-dimensional system
and two initial conditions
Evolving these two states until \(T=1\) yields final states
and we can plot the trajectories towards those final states below (left).
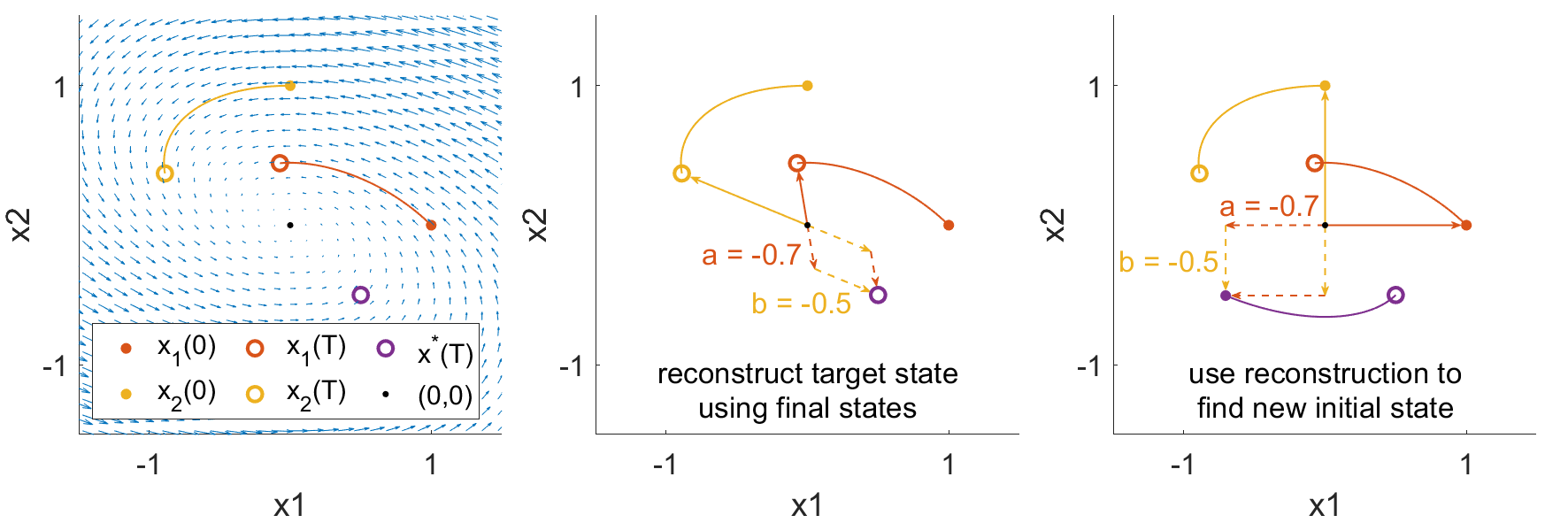
Now, suppose we wanted the system to actually reach a different final state, say
Because of the linearity of the system, we know that weighted sums of the initial states map to the same weighted sums of the trajectories. We can reverse this idea and write the desired final state as a weighted sum of trajectories,
and solve for the weights through simple matrix inversion
Then, if we use the same weighted sums of the initial states, then the new initial state is guaranteed to reach the desired target state,
due to the properties of linearity such that
As we can see, we did not have to do any guesswork in solving for the initial state that yielded the desired final state. Instead, we reconstructed the final state from a basis of final states, and took advantage of the linear property of the impulse response to apply that reconstruction to the initial states. This reconstruction using basis vectors and linearity is the core principle behind network control theory.
an easier approach
While the previous reconstruction example was useful, the linearity of the impulse response actually allows us to solve the problem much faster, because at the end of the day, the impulse response is simply a linear system of equations,
So, we know \(A,\) and we know the desired target state, \(\mathbf{x}(T),\) so we just multiply both sides of the equation by the inverse of \(e^{AT}\) to yield the correct initial state
And… that’s kind of it. And fundamentally, the control of these systems uses the exact same idea. That is, we find some linear operation that takes us from the control input to the final state, then solve for the input using some fancy versions of matrix inverses.
Controlled Dynamics
Until now, we have worked with LTI dynamics, which we write as
When we say control, we intend to perturb the system using some external inputs, \(u_1(t), u_2(t),\dotsm,u_k(t),\) that we will collect into a vector \(\mathbf{u}(t).\) These inputs might be electromagnetic stimulation from transcranial magnetic stimulation (TMS), some modulation of neurotransmitters through medication, or sensory inputs. And of course, these inputs don’t randomly affect all brain states separately, but have a specific pattern of effect based on the site of stimulation, neurotransmitter distribution, or sensory neural pathways. We represent this mapping from stimuli to brain regions through vectors \(\mathbf{b}_1,\mathbf{b}_2,\dotsm,\mathbf{b}_k,\) which we collect into an \(N\times k\) matrix \(B.\) Then our new controlled dynamics become
So now we have a bit of a problem. We would like to write \(\mathbf{x}(t)\) as some nice linear function as before, but how do we do this? The derivation requires a bit of algebra, so feel free to skip it!
derivation of the controlled response
So the first thing we will try to do is, as before, move all of the same variables to one side. So first, we will subtract both sides by \(A\mathbf{x}\)
Then, as before, we want to integrate the time derivative. However, simply integrating both sides will yield a \(\int A\mathbf{x}\) term, which we do not want. To combine the \(\dot{\mathbf{x}}\) and \(A\mathbf{x}\) terms, we will first mutiply the equation by :math:e^{-At},
and notice that we can actually perform the reverse of the product rule on the left-hand side. Specifically, \(\frac{\mathrm{d}}{\mathrm{d}t} e^{At}\mathbf{x} = e^{At}\dot{\mathbf{x}} - e^{At}A\mathbf{x}\) (small note, \(e^{-At}A = Ae^{-At}\) because a matrix and functions of that matrix commute). Substituting this expression into the left-hand side, we get
Now we are almost done, as we integrate both sides from \(t = 0\) to \(t = T\) to yield
Finally, we isolate the term \(\mathbf{x}(T)\) by adding both sides of the equation by \(\mathbf{x}(0),\) and multiplying through by \(e^{AT}\) to yield
We notice that the first term, the “natural” term, is actually our original, uncontrolled impulse response. We also notice that the second term, the “controlled” term, is just a convolution of our input, \(\mathbf{u}(t),\) with the impulse response. For conciseness, we will write the convolution using a fancy letter \(\mathcal{L}(\mathbf{u}) = \int_0^T e^{A(T-t)} B\mathbf{u}(t) \mathrm{d}t,\) and rewrite our controlled response as
some intuition for the controlled response
We can gain some simple intuition by rearranging the controlled response a little
If we look closely, we notice that the controlled response simply makes up the difference between the natural evolution of the system from its initial state, and the desired target state. To visualize this equation in our previous 2-dimensional example, we mark the initial state and natural evolution of the initial state in orange, and the desired target state in purple. The controlled response is algebraically responsible for making up the gap between the initial and target state.
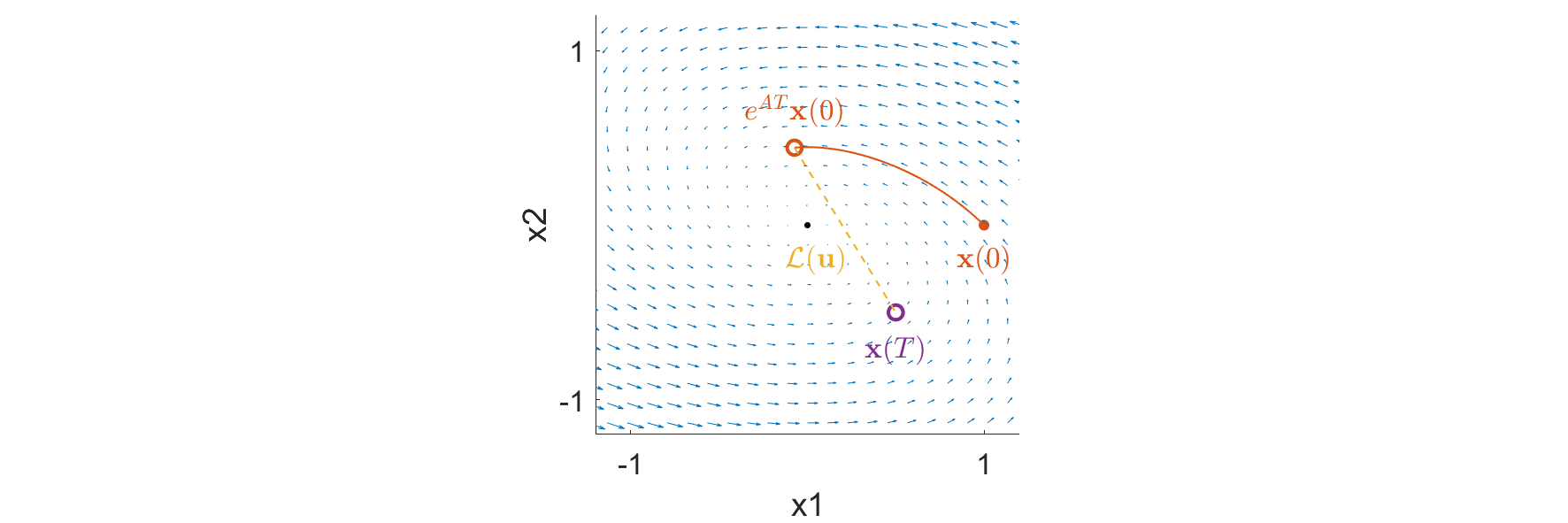
The Potential of Linear Controlled Response
So now we reach the final question: how do we design the controlled response, \(\mathbf{u}(t),\) that brings our system from an initial state \(\mathbf{x}(0)\) to a desired target state \(\mathbf{x}(T)\) ? And the great thing about this question is that we already know how to do it because the controlled response is linear. By linear, we again mean that for some input \(\mathbf{u}_1(t)\) that yields an output \(\mathbf{y}_1 = \mathcal L(\mathbf{u}_1(t)),\) and another input \(\mathbf{u}_2(t)\) that yields an output \(\mathbf{y}_2 = \mathcal L(\mathbf{u}_2(t)),\) we have that
This fact comes from the fact that the convolution operator is linear.
a simple 2-state example
So let’s try to derive some intuition with the same 2-state example as before, but now our system will have a controlled input such that
The natural trajectory of the system is shown as the blue curve, while the first controlled trajectory when \(u_1=1\) is shown in the red curve, and the second controlled trajectory when \(u_2=1\) is shown in the yellow curve (left).
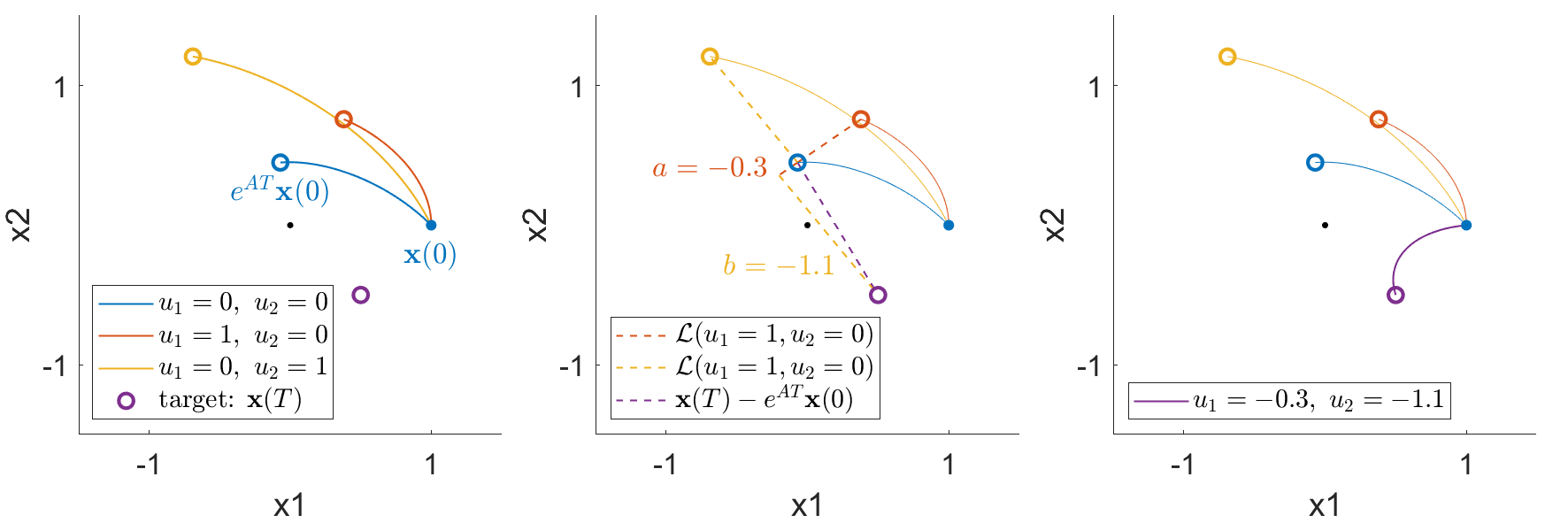
Now, we have to be careful about exactly what is linear. And the thing that is linear is the convolution operator, \(\mathcal{L}(\mathbf{u}) = \int_0^T e^{A(T-t)} B\mathbf{u}(t) \mathrm{d}t.\) This operator takes the control input, \(\mathbf{u}(t),\) as its input, and outputs the difference between the final state, \(\mathbf{x}(T),\) and the natural, uncontrolled evolution, \(e^{AT} \mathbf{x}(0).\) Hence, we have to speak about the states relative to the natural, uncontrolled evolution.
So when we look at the effect of the first controlling input \(u_1=1,\) we are looking at the difference between the controlled final state (open orange circle) from the natural final state (open blue circle). Similarly, when we look at the effect of the second controlling input \(u_2 = 1,\) we are looking at the difference between the controlled final state (open yellow circle) from the natural final state (open blue circle). And if we want to reach a new target state (open purple circle), we use these differences in controlled trajectories (dashed red and yellow lines) as the basis vectors, and find the weighted sums that yield the difference between the target state and the natural final state (dashed purple line), which yields \(u_1 = -0.3, u_2 = -1.1.\) And when we control our system using this linear combination of inputs, we see that the trajectory indeed reaches the desired target state (right).
Minimum Energy Control
Of course, this process is all a bit tedious, because we first have to simulate controlled trajectories, then take combinations of those trajectories. Is there a faster and easier way to solve for control inputs that perform a state transition without having to run simulations? The answer is yes, because the controlled response operator \(\mathcal L(\mathbf{u})\) is linear, but requires a bit of care.
So first, let’s think about a typical linear regression problem, \(M\mathbf{v} = \mathbf{b},\) where \(M\) is an \(k \times n\) matrix, \(\mathbf{v}\) is an \(n\) dimensional vector, and \(\mathbf{b}\) is an \(k\) dimensional vector,
One solution to this regression problem is \(\mathbf{v}^* = A^\top (AA^\top)^{-1} \mathbf{b},\) where \(A^+ = A^\top (AA^\top)\) is called the pseudoinverse. In fact, this pseudoinverse is quite special, because when a solution to the system of equations exists, \(\mathbf{v}^*\) is the smallest, or least squares solution, where the magnitude is measured simply by the inner product, which in the case of \(n\)-dimensional vectors is
where the subscript \(\mathbb R^n\) indicates that the inner product is on the space of \(n\)-dimensional vectors. We can extend the exact same equations to our control problem. Explicitly, instead of a matrix \(M,\) we will use our control response operator \(\mathcal L.\) Instead of a vector of numbers \(\mathbf{v},\) we will use a vector of functions \(\mathbf{u}(t).\) And instead of dependent variable \(\mathbf{b},\) we will use the state transition \(\mathbf{x}(T) - e^{AT}\mathbf{x}_0.\) Then the solution to our least squares solution will be
Now, you may have noticed a slight problem, which has to do with the fact that our inputs are no longer vectors of numbers, but rather vectors of functions. This problem shows up in the transpose, or adjoint \(M^\top.\) In our linear regression example, because the operator \(M\) is a matrix, it makes sense to take it’s tranpose. And this transpose satisfies an important property, which is that it preserves the inner product of input and output vectors. So if \(M\mathbf{v}\) is an \(n\)-dimensional vector, and \(M^\top\mathbf{b}\) is an \(k\)-dimensional vector, then \(M^\top\) is defined such that
And when we are thinking about our control response operator \(\mathcal L,\) we can actually do the same thing! First, we see that \(\mathcal L\) is not mapping vectors to vectors as \(M,\) but rather maps functions \(\mathbf{u}(t)\) to vectors. So we first need to define the inner product of functions, which is simply
where the subscript \(\mathbb \Omega^k\) indicates that the inner product is on the space of \(k\)-dimensional functions. Now, to find the adjoint of operator \(\mathcal L,\) we have to satisfy the same inner product relationship (where we call \(\mathbf{b} = \mathbf{x}(T)-e^{AT}\mathbf{x}(0)\) for brevity)
and we see that for the left and right sides to be equal, the adjoint must be equal to \(\mathcal L^* = B^\top e^{A^\top (T-t)}.\) Intuitively, this makes sense because if the original operator \(\mathcal L\) took functions of time as inputs and output a vector of numbers, then the adjoint should take vectors of numbers as inputs and output functions of time. Finally, plugging this adjoint back into our solution, we get
where for convenience, we will refer to the bracketed quantity as the controllability Gramian. To compute the magnitude of this control input, we simply take the norm of this solution to get
final equations
So here we are! After some derivations, we can compute the control input \(\mathbf{u}^*(t)\) that brings our system \(\dot{\mathbf{x}} = A\mathbf{x} + B\mathbf{u}\) from an initial state \(\mathbf{x}(0)\) to a final state \(\mathbf{x}(T)\) with minimal norm input as
which costs the minimum energy
a simple 2-dimensional example
To provide a bit of intuition for the control process, we look again at our simple 2-dimensional linear example, but with only one control input, \(u_1(t),\) along the \(x_1\) direction
This means that we can only push our system along the \(x_1\) direction, and have to rely on the internal dynamics to change the \(x_2\) state. The natural trajectory (blue), controlled trajectory (orange), and control input (orange arrows) are shown in the left subplot below.
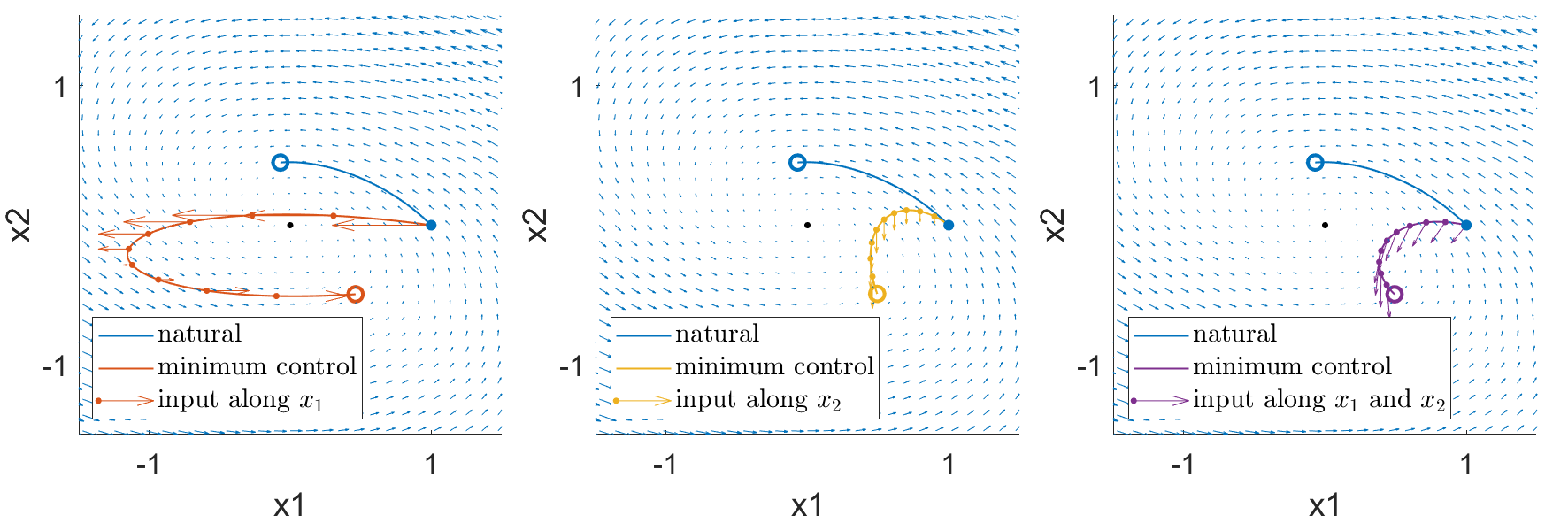
We observe that the state takes a rather roundabout trajectory to reach the target state, because the only way for the system state \(x_2\) to move downward is to push the state \(x_1\) to a regime where the natural dynamics allow \(x_2\) to decrease. Now, if we define a different control system where we can only influence the dynamics along the \(x_2\) state such that
then we get the trajectory in the center subplot. Notice that the dynamics don’t push the system straight downard, but rather follows the natura dynamics upwards for a while before moving downard. This is because it costs less energy (input) to fight the weaker natural upward dynamics near the center of the vector field, as opposed to fighting the stronger natural upward dynamics near the right of the vector field.
Finally, if we are able to independently influence both of the system states,
then we get the controlled trajectory and inputs in the right subplot.